DNA Is Constantly Changing through the Process of Mutation - www.nature.com/scitable/topicpage/dna-is-constantly-changing-through-the-process-6524898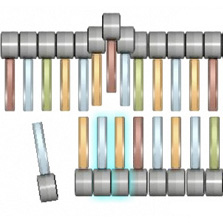
DNA is a dynamic and adaptable molecule. As such, the nucleotide sequences found within it are subject to change as the result of a phenomenon called mutation. Depending on how a particular mutation modifies an organism's genetic makeup, it can prove harmless, helpful, or even hurtful. Sometimes, a mutation may even cause dramatic changes in the physiology of an affected organism. Of course, in order to better understand the varying effects of mutations, it is first necessary to understand what mutations are and how they occur.
Where do mutations occur?Mutations can be grouped into two main categories based on where they occur: somatic mutations and germ-line mutations. Somatic mutations take place in non-reproductive cells. Many kinds of somatic mutations have no obvious effect on an organism, because genetically normal body cells are able to compensate for the mutated cells. Nonetheless, certain other mutations can greatly impact the life and function of an organism. For example, somatic mutations that affect cell division (particularly those that allow cells to divide uncontrollably) are the basis for many forms of cancer.
Germ-line mutations occur in gametes or in cells that eventually produce gametes. In contrast with somatic mutations, germ-line mutations are passed on to an organism's progeny. As a result, future generations of organisms will carry the mutation in all of their cells (both somatic and germ-line).
What kinds of mutations exist?Mutations aren't just grouped according to where they occur — frequently, they are also categorized by the length of the nucleotide sequences they affect. Changes to short stretches of nucleotides are called gene-level mutations, because these mutations affect the specific genes that provide instructions for various functional molecules, including proteins. Changes in these molecules can have an impact on any number of an organism's physical characteristics. As opposed to gene-level mutations, mutations that alter longer stretches of DNA (ranging from multiple genes up to entire chromosomes) are called chromosomal mutations. These mutations often have serious consequences for affected organisms. Because gene-level mutations are more common than chromosomal mutations, the following sections focus on these smaller alterations to the normal genetic sequence.
Base substitutionBase substitutions are the simplest type of gene-level mutation, and they involve the swapping of one nucleotide for another during DNA replication. For example, during replication, a thymine nucleotide might be inserted in place of a guanine nucleotide. With base substitution mutations, only a single nucleotide within a gene sequence is changed, so only one codon is affected (Figure 1).
Although a base substitution alters only a single codon in a gene, it can still have a significant impact on protein production. In fact, depending on the nature of the codon change, base substitutions can lead to three different subcategories of mutations. The first of these subcategories consists of missense mutations, in which the altered codon leads to insertion of an incorrect amino acid into a protein molecule during translation; the second consists of nonsense mutations, in which the altered codon prematurely terminates synthesis of a protein molecule; and the third consists of silent mutations, in which the altered codon codes for the same amino acid as the unaltered codon.
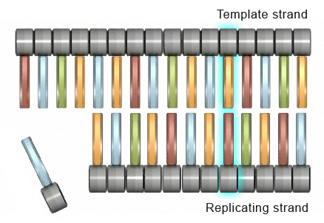
Insertions and deletionsInsertions and deletions are two other types of mutations that can affect cells at the gene level. An insertion mutation occurs when an extra nucleotide is added to the DNA strand during replication. This can happen when the replicating strand "slips," or wrinkles, which allows the extra nucleotide to be incorporated (Figure 2).
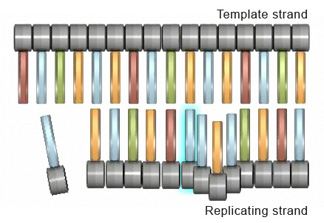
Strand slippage can also lead to deletion mutations. A deletion mutation occurs when a wrinkle forms on the DNA template strand and subsequently causes a nucleotide to be omitted from the replicated strand (Figure 3).
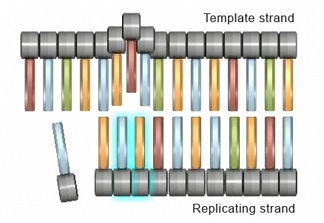 Frameshift mutations
Frameshift mutations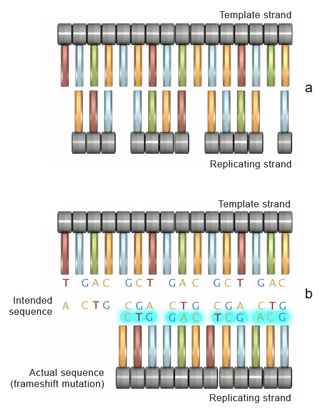
Insertion or deletion of one or more nucleotides during replication can also lead to another type of mutation known as a frameshift mutation. The outcome of a frameshift mutation is complete alteration of the amino acid sequence of a protein. This alteration occurs during translation because ribosomes read the mRNA strand in terms of codons, or groups of three nucleotides. These groups are called the reading frame. Thus, if the number of bases removed from or inserted into a segment of DNA is not a multiple of three (Figure 4a), the reading frame transcribed to the mRNA will be completely changed (Figure 4b). Consequently, once it encounters the mutation, the ribosome will read the mRNA sequence differently, which can result in the production of an entirely different sequence of amino acids in the growing polypeptide chain.
To better understand frameshift mutations, let's consider the analogy of words as codons, and letters within those words as nucleotides. Each word itself has a separate meaning, as each codons represents one amino acid. The following sentence is composed entirely of three-letter words, each representing a three-letter codon:
THE BIG BAD FLY HAD ONE RED EYE AND ONE BLU EYE.Now, suppose that a mutation eliminates the sixth nucleotide, in this case the letter "G". This deletion means that the letters shift, and the rest of the sentence contains entirely new "words":
THE BIB ADF LYH ADO NER EDE YEA NDO NEB LUE YE.This error changes the relationship of all nucleotides to each codon, and effectively changes every single codon in the sequence. Consequently, there is a widespread change in the amino acid sequence of the protein. Lets consider an example with an RNA sequence that codes for a sequence of amino acids:
AUG AAA CUU CGC AGG AUG AUG AUGWith the triplet code, the sequence shown in figure 5 corresponds to a protein made of the following amino acids:
Methionine-Lysine-Leucine-Arginine-Arginine-Methionine-Methionine-Methionin
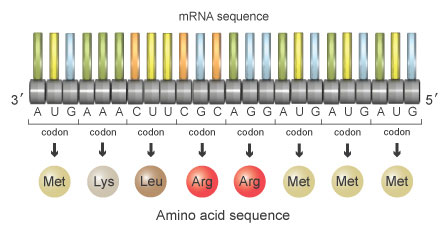
Now, suppose that a mutation occurs during replication, and it results in deletion of the fourth nucleotide in the sequence. When separated into triplet codons, the nucleotide sequence would now read as follows (Figure 6):
AUG AAC UUC GCA GGA UGA UGA UGThis series of codons would encode the following sequence of amino acids:
Methionine-Asparagine-Phenylalanine-Alanine-Glycine-STOP-STOP
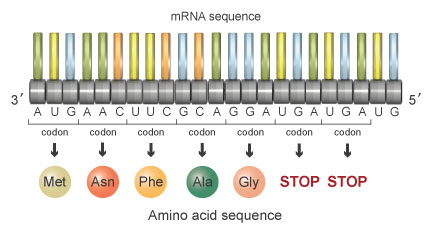
Each of the stop codons tells the ribosome to terminate protein synthesis at that point. Consequently, the mutant protein is entirely different due to the deletion of the fourth nucleotide, and it is also shorter due to the appearance of a premature stop codon. This mutant protein will be unable to perform its necessary function in the cell.
What causes mutations?Mutations can arise in cells of all types as a result of a variety of factors, including chance. In fact, some of the mutations discussed above are the result of spontaneous events during replication, and they are thus known as spontaneous mutations. Slippage of the DNA template strand and subsequent insertion of an extra nucleotide is one example of a spontaneous mutation; excess flexibility of the DNA strand and the subsequent mispairing of bases is another.
Environmental exposure to certain chemicals, ultraviolet radiation, or other external factors can also cause DNA to change. These external agents of genetic change are called mutagens. Exposure to mutagens often causes alterations in the molecular structure of nucleotides, ultimately causing substitutions, insertions, and deletions in the DNA sequence.
What are the consequences of mutations?Mutations are a source of genetic diversity in populations, and, as mentioned previously, they can have widely varying individual effects. In some cases, mutations prove beneficial to an organism by making it better able to adapt to environmental factors. In other situations, mutations are harmful to an organism — for instance, they might lead to increased susceptibility to illness or disease. In still other circumstances, mutations are neutral, proving neither beneficial nor detrimental outcomes to an organism. Thus, it is safe to say that the ultimate effects of mutations are as widely varied as the types of mutations themselves.
Watch these videos for a summary of the different types of gene-level mutation at
www.nature.com/scitable/topicpage/dna-is-constantly-changing-through-the-process-6524898




